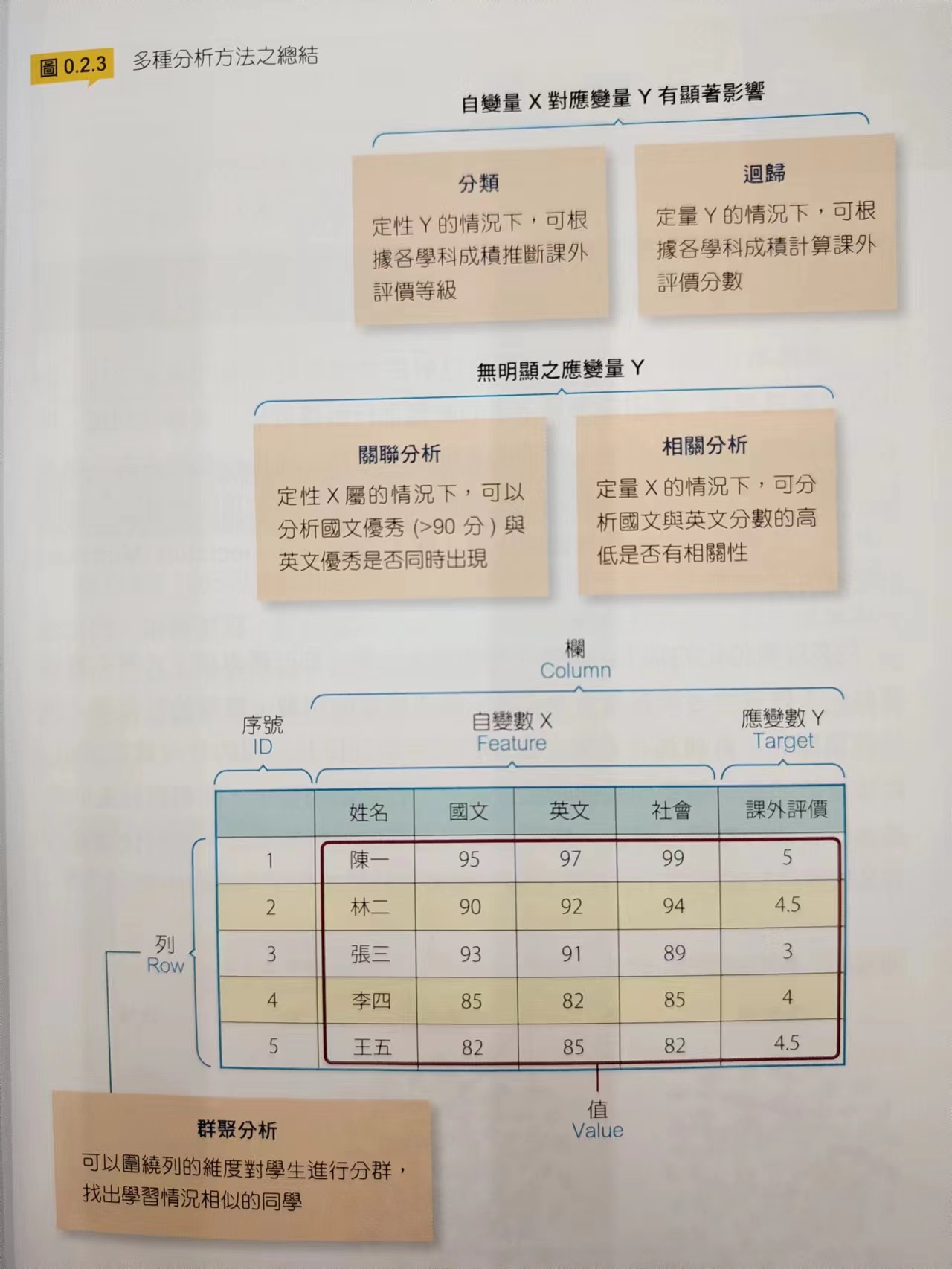
数据表格:栏、列、值
数据类型:数值型、类别型、文字型、时间型
数据属性:定性qualitative 定量quantitative
衡量尺度:
名目资料:定性,数字的大小没有意义。
顺序资料:定性,数字的大小有意义,但数字之间的差距没有意义。
区间资料:定量,数字间的差距有意义,归属有那个区间。
比例资料:定量,0等于“完全没有”。
五种常见的分析目标:
| 分析对象 | 分析目标 | 范例 | |
|---|---|---|---|
| 栏 | x为定性 | 关联association | 判断2个x是否同时出现 |
| 栏 | x为定量 | 相关correlation | 判断2个x是否同升同降 |
| 栏 | y为定性 | 分类classification | 判断是否为第一名 |
| 栏 | y为定量 | 回归regression | 预测每个同学的名次 |
| 列 | 群聚clustering | 找各科分数接近的人 |
数据分析步骤:
1,数据收集:按照决策需求与产业知识决定自变量x,应变量y
2,数据预处理:常见的数据预处理有数据转换,填补数据中的缺失值(M issing Data ),删除离群值(Outlier),数据标准化(Standardization),数据正规化(Normalization)等。
3,数据分割:数据分成3部分,训练、验证、测试,如果使用交叉验证,则是把训练和验证部分的资料合并,再均分成n份,然后循环使用n等分的1份资料作为验证资料,其他作为训练资料,提升机器学习的验证效果。常见切割比例如下表:
| 训练 | 验证 | 测试 | 备注 |
|---|---|---|---|
| 80% | 10% | 10% | |
| 70% | 20% | 10% | |
| 70% | 15% | 15% | |
| 80% | 80% | 20% | 交叉验证 |
| 90% | 90% | 10% | 交叉验证 |
4,模型训练:使用恰当的机器学习演算法对训练数据进行分析,这一过程也称为拟合(Fitting),最终产出为模型(Model)。
5,模型验证:将验证数据中的自变数x输入训练好的模型中,得到预测值Y,y称为拟合值。
6,模型评估:比较应变数y的值和预期值y之间的差异性。y的属性不同,则评估的方式也不同。
y是定性,常用的评估方法混浠矩阵(Confusion Matrix)、准确度(Accuracy)、ROC曲线下方面积(AUC)等
y是定量,常用的评估方法均分根误差(RMSE)、平均绝对误差(MAE)、判定系数(R2)等
7,模型未达标准。肯能的调整方式有增加训练次数、调整演算法中的超参数、更换其他演算法、重新处理数据集、扩大数据量等。当符合标准时,即可进入测试阶段。
8,模型测试。会出行两种不好的情况,拟合不足,拟合过度。
分析方法:
群聚分析
关联分析
相关分析
分类
回归
时间序列分析